Over the years my environment has grown in leaps and bounds for various reasons. Many years ago everything just ran off one linux box. NAS, downloading and backups. Everything. Over time this has swelled up and is now beyond a joke.
There was at time when I ran a single esx host with passthrough PCIe card to an opensolaris VM for NAS, and a linux vm for everything else. Maybe a windows VM for the vsphere client and that was it.
Now I’m at a stage where two decent speced hosts are over loaded (always RAM) and a collection of supporting VM’s are eating up a substantial amount of these resources. Part of this reason is to keep my skills current and ahead of my workplace - since I don’t get adequate time to learn at work, and the environments available aren’t suited to some of the experimenting that’s really needed. Also anything cloud related is impossible due to network security and network performace.
However I have labbed up vmware vsan and learned a heap over the 13 months I’ve been running it - yeah it’s been that long. 2 node ROBO deployment with witness appliance (on a third host). This has improved in leaps and bounds from the 6.1 vsan release I was on, up to the 6.6 I’m on today. It’s not without issue of course. I’ve corrupted vmdk’s and in at least one instance lost a vmdk entirely. I would NOT recommend running the 2 node ROBO design on a business site. But compared to a stand alone host it’s probably still worth a go, but be aware of the limits and stick to the HCL and watch the patch releases closely - many have been for data corruption issues. Fortunately patching is simple with the vCenter server appliance (VCSA) now having update manager built in. For now though, the VSAN UI is entirely in the old flash UI, and not the new HTML5 UI. Vsphere 6.5 is a great improvement in every way on the versions before it.
I’ve also labbed up OnCommand Insight which is an amazing product. It’s only issue is it’s way too expensive. This product has a front end real time UI and back end data warehouse for scheduled or adhoc reports. I’ve only labbed up the front end, as it’s great for identifying issues in the Vmware stack and just general poking around at where your resources have gone. For home though, the VM does eat heaps of resources - 24GB ram and 8 cores for the main server, and 24GB ram and 2 cores for the anomaly detection engine (I should see if I can lower that ram usage).
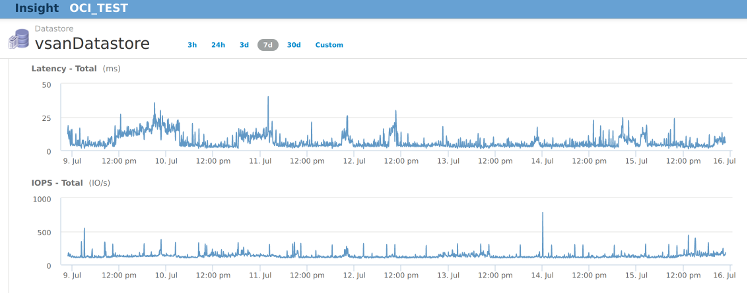
vRealize Log Insight is similar to Splunk but free (ish) from vmware (depending on your licensing). This eats up lots of resources at home too - 20% cpu all the time (2 cores assigned). It’s default sizing manages nearly 12 months of logs in it, which is way more than could ever need.
Other Netapp bits I labbed up is the Netapp simulator and associated bits - OnCommand unified manager and workflow automation. A handful more vm’s there, and I’ve got 2 versions of the simulator too due to testing upgrading and compatibility. Just not running both at once except when I need to to test something specific.
NetApp Altavault is also one I’ve been playing with. This gives you a CIFS/NFS target locally with a cache and stashes it all in the cloud (s3 bucket style storage). For a while I was keen to utilise this for a cloud backup of my data, however the VM is pretty heavy (24GB ram, and minimum 2TiB cache disk (8TiB recommmended for the 40TiB model)) and the egress pricing out of the cloud is still higher than I’d like. Still, it’s a great product and works fine.
At one stage I had labbed up Vmware NSX too, but due to some issues (which I now believe have been addressed) I had to remove it. Since then I haven’t returned to have another go.
Obviously not all of this needs to run all the time, but in many ways it’s less useful to have them not running constantly due to gaps in the data, or even the time necessary to start up the environment to test again before shutting it down. Or daily tasks within the tools which wouldn’t run if it’s not left running. Yeah yeah, another automation problem.

Ok so far thats just a numbers game. Too many VM’s, too much disk. Trying to do too much at once. Can’t fault that logic.
The down side is this situation has occurred only because I had the capacity for it to. If I didn’t have 2 decent ESX hosts or a few TB spare for VM’s this would have never occurred. The ongoing challenge now is to rationalise the size of the VM’s down to their minimum and keep things up to date (more pets again by the looks).
Or do I just toss it all in the bin and go back to basics in the interests of costs, time and overheads?
