A while back I bought some OCZ Vertex 2 (sandforce based) ssd’s, which dropped in price 2 weeks later (as expected). I put one into my desktop when I rebuilt it, which was great, now there’s definitely no bottleneck on IO, and even though it’s only got 4gb of ram (shared video too - so more like 3.5gb) it now has fast swap. Obviously you don’t want to swap ever, but if you do start dipping into swap you’d prefer it to be fast and not impacted by other random IO on the disk, so the ssd is great.
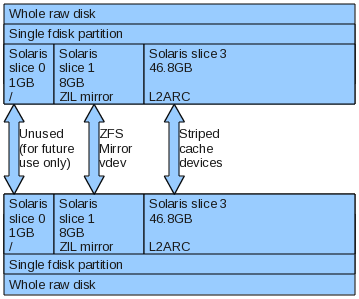
The other 2 ssd’s I bought to use as a cache on my primary filer box. ZFS lets you have external caches for both read and write. The write cache is like the journal on a classic file system and is called the ZFS Intent Log (or ZIL). When the ZIL is external to the zpool, it’s commonly called a separate log, or slog device. As the file system is built with failure in mind, you need to be aware of the various failure situations if you lose different devices. Losing the ZIL is bad, but no longer catastrophic (it used to be). Now you’ll just lose all uncommitted changes to the disk, which is fine, and it won’t corrupt the pool. Obviously losing data is bad, and it’s always been recommended that the ZIL be on mirrored storage. To select the size of the ZIL there are some calculations related to how much data can be written in 10 seconds (and it’s flushed out at least every 10 seconds), and also taking into account system RAM size too. Aiming way too high (but catering for growth maybe) I set mine at 8gb, mirrored.
The rest of the ssd’s were to become the read cache, known as the L2ARC cache. The ARC (adjustable replacement cache) cache is a purely in ram cache, and L2ARC is the second level version to be used on fast secondary storage devices like 15K drives or ssds. Objects in this cache are still checksummed, so a device going bad can’t corrupt anything (if cache is bad, just read off the primary storage). Due to this there is no point mirroring the read cache and by adding multiple devices you essentially stripe your cache, which is good. So the 2 ssd’s were sliced up (Solaris partitions) with an 8gb slice for the mirrored ZIL, and the rest for the L2ARC. Using 60gb ssd’s I’ve now got over 90gb of high speed read cache, the theory is this cache could read at over 500MB/s, in practice it’s hard to tell. At least the ssd’s are rated at 50000 IOPS for 4k random writes.
Half the idea behind all this was to improve power management. Say you’re watching a film, the whole file can be pre-read into cache and then while watching, it can be served purely from the cache while the main disks have spun down. ZFS apparently has some very neat caching algorithms in it, and I’m probably not seeing the best behaviour because the box doesn’t have sufficient system ram (only 2gb), but in it’s defence it is a 5 year old box. A rebuild (apart from disks) is long overdue.
So to actually do all this, once the disk is sliced up (using format) you can simply add the log and cache vdev’s as follows (with your device names):
|
|
Or if you were building the zpool from scratch (say with 8 disks) and all the above craziness (as you do):
|
|
Which would leave you with a pool along these lines (once you’ve put heaps of data on it):
|
|
Later if you ever need to, you can remove these cache/slog devices, say you wanted to use the ssd’s elsewhere or needed the sata ports for other spinning disks. Cache can be removed from any version, and slog/zil can be removed as long as you’re on zpool version 19 or above. You just have to be careful which command you use, like when adding devices as they each have different meaning.
zpool remove - removes a cache device or top level vdev (mirror of logs only). Mirror vdev name comes from the zpool status output.
|
|
zpool detach - detaches a disk from a mirror vdev (can return it to a single device vdev if you remove the second last disk). Example below detaches c3d0s1 from a mirror, if it’s not a mirror the command will error out. Detach works on any mirror vdev, not just logs.
|
|
zpool attach - makes a mirror out of an existing vdev (single device, or mirror) Example attaches new device c3d0s1 as a mirror of already present device c2d0s1. Attach also works on any vdev, not just logs.
|
|
After using ZFS for over 2 years now I’ve come to really appreciate it. There’s a definite learning curve to it, but no more than equivalent on Linux. Linux Raid + LVM + <file system of choice> + how to resize/reshape and so on. Actually zfs might be simpler, as all the commands are clearly documented in one place and behave all the same. The best part of ZFS is knowing your data is not rotting away on disk, and the very easy incremental replication, and snapshots, and Solaris’s smoking fast NFS server, and and and